XFSSGI��s XFS is a much more complicated file system. Why is that complication needed? To understand that, we need to know the problems with FFS and its ilk (Ext2). These problems are stability under power loss/system crash and scalability. You may notice that FFS has no way of dealing with system crashes. This file system must be mounted sync, meaning programs have to wait for writes to finish before moving on, for it to be stable during power loss. This is a big problem. Mounting file systems synchronously is just not acceptable for today��s systems, its simply too slow. The second problem is scalability and speed. FFS uses lists to store inodes and cylinder groups. This means the file system scales O(n), period. For those who have not taken discrete math (for shame...) scaling O(n) means that as the size of the file system increases, the search time increases at the same rate. This means bad mojo for big file systems. Another note, FFS directories are also stored as lists of file names, so try to stay away from big folders.
So, FFS and its like are not good enough. What��s next? XFS is one of the options. The first thing XFS does is to replace FFS��s lists with something called a B+Tree. B+Trees are complex. Let me rephrase that. B+Trees are very, very complex. First, lets look at what a tree is. Basically, it is a data structure that takes the form of an actual tree, with each node of the tree holding some sort of data and having two or more "branches" to other nodes. For the sake of this discussion, lets assume we are dealing with a "Binary Tree," where each "node" of the tree has at most 2 branches. The following picture shows this.
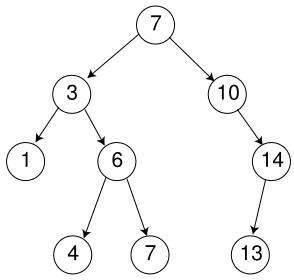 [7] [7]
Next, lets look at a Binary Search Tree. This is a binary tree where the left branch is "less" than the node and the right branch is "greater" than the node. This cuts down search time significantly, because you can cut out whole parts of the tree when searching. Lets say its a tree of numbers. You go to the root node, its 5. However, your looking for 3, so you take the left branch. The next node is 2, so you take the right branch and boom, 3. Now imagine if that was a list. What if the 3 was at the end of the list? It is easy to see how much better this is.
There is a large problem though, these trees can become unbalanced. For example, lets take numbers 1 through 5. So, lets make our root node, 5, the node to the left 4, and so on. This is just a sorted list and we are suddenly right back where we started. There are types of trees that try to deal with that by introducing balancing routines. One of these is called a B+Tree. I am not going to define what balancing routine it uses, because it is obscenely complicated and not important for our discussion. Suffice to say that it does work.
B+Trees have some other interesting attributes.
- They are NOT binary trees. They can and many times do have more than 2 branches.
- All nodes don��t have data stored in them. In fact, only one type of node has data, the "leaves." These are nodes at the "bottom" of the tree that are only connected to a node above them. They don��t have any "child" nodes, only data.
- All "leaf" nodes are at the same level of the tree and are connected to each other, so you can move between them without having to go back up into the tree.
So, a B+Tree is a type of balanced tree, with these extra features to ensure better performance on discs. XFS uses a ton of these. For example, XFS stores inodes in B+Trees. You can imagine that searching a balanced binary tree, in this case a B+Tree, for a file is a lot more efficient and scalable than searching a list. So, now that we understand the data structure on which XFS is based, we can look at the basic design of the file system.
The Design Of XFSLet��s start with the XFS version of cylinder groups, allocation groups. These are meant to solve the same thrashing problem we saw before. There is another reason for allocation groups in XFS, they are completely autonomous. The kernel can interact with multiple allocation groups at the same time. This makes XFS very multi-thread friendly. Like in FFS, these allocation groups store the inode list for their region of the drive. However, in XFS these inodes are stored in B+Trees and actually are stored in two B+Trees, one for free inodes and the other for used inodes. This makes creating a new file a very efficient operation, since you don��t have to search for a free inode. Now, lets talk about the inodes themselves. XFS is designed for large files. Because of this, the XFS inodes use "extents" to define data block ranges. An extent is a starting address on the disc and an offset from that address. These are much more efficient than actually listing all the address of the data blocks which make up a file. Extents are really better for long continuous stretches of data. They are very poor for fragmented discs, as short stretches of data turn an extent list into just a list of addresses where data is stored, just like the old system. XFS has an interesting way of promoting defragmented files called delayed allocation. XFS waits as long as possible to actually write data to the disc. Sure, it reserves the amount of space it needs, but it doesn��t actually define where that space is going to be on the disc. This means if your appending a lot of data to the end of a file, it will wait and be able to intelligently reserve continuous space for this appended data.
So, thats how XFS deals with the scalability and speed problems of FFS. Dealing with the power loss problem is at least as interesting. XFS uses what is called a metadata journal. Basically, this means that every disc transaction is written in a journal before it is written to the disc and then marked as "done" in the journal when it finishes. If the system crashes during the writing of the journal entry, that incomplete entry can be ignored since the data on the disc has not been touched yet and if the journal entry is not marked done, then that operation can be rolled back to preserve disc integrity. Its a very nice system. As stated above, XFS practices a type of journaling called "metadata journaling." This means only the inodes are journaled, not the actual data. This will preserve the integrity of the file system, but does not preserve the integrity of the data. As noted, the actual data tends to be considered rather boring and unimportant in file system design. [5] [4]
Finally, lets look at the XFS superblock. This is fairly similar to the FFS superblock, except it again uses a B+Tree to store the allocation group references. The only "odd" thing about the XFS superblock is that because of where it is in the partition (right at the beginning), you cannot install a boot block to an XFS partition. There is simply no room for it. So, if you use XFS, you must install boot blocks to the MBR.
Benefits of XFSSo, what does this design give XFS? Well, scalability is obvious. UFS scales well to around 1 TB, NTFS to around 2 TB and XFS to around 18-19 million TB (these numbers are theoretical, I am just talking about the design here). Small difference there. It is also a very fast file system, allowing reads of up to 7 GB/sec. One thing some might find disturbing about the file system, is delayed allocation. It does this for good reasons, but the delay means that while a crash will not destroy FS, it might result in significant loss of data that has not yet been written to the disc. [1]
ConclusionThat is XFS: a fast, modern and extremely scalable file system. If you are storing huge numbers of large files on gigantic discs, give XFS a try. Even if you aren��t you might want to try it out, as some people have gotten great results using it. Personally, I am waiting to decide on my favorite FS. Reiser4 and ZFS are still lurking out there and they will be covered next. Oh yes...I��m front-selling.
References
Written by Mad Penguin™ System Administrator, Narayan Newton |
